이번 테크블로그에서는 Datalab 및 BigQuery를 이용한 빅 데이터 분석에 대해 살펴보겠습니다.
Google BigQuery는 대규모(페타바이트 급) 데이터 분석을 위한 빠르고 경제적인 완전 관리형 기업용 데이터 웨어하우스입니다.
관리할 인프라가 없기 때문에 익숙한 SQL을 이용하여 데이터를 분석해 의미 있는 유용한 정보를 찾는데 집중할 수 있으며, 데이터 베이스 관리자가 필요하지 않습니다.
Cloud Datalab은 데이터 탐색, 분석, 시각화를 위한 도구로 Python, SQL 과 같은 익숙한 언어를 이용하여, 데이터 분석 및 변환을 Interactive하게 수행합니다.
뉴스레터 가입
클라우드 관련 최신 소식을 업데이트 받으실 수 있습니다.
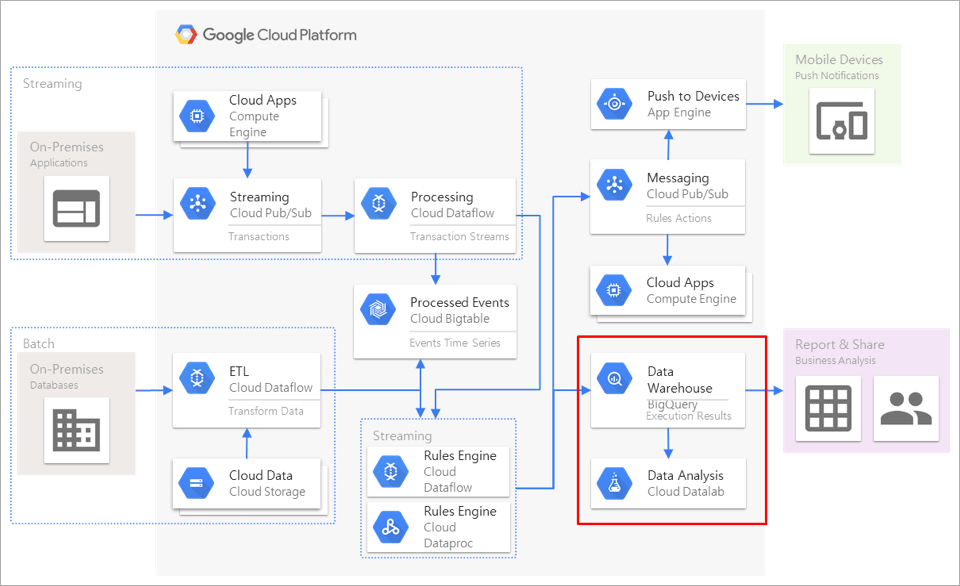
그림1 빅데이터 분석 표준 아키텍처
이 글에서는 Google BigQuery 및 Cloud Datalab을 사용하여 대규모 (1 억 3 천 7 백만 행) 출생 데이터 세트를 분석하는 실습을 수행합니다. 실습에서는 다음과 같은 과정을 수행합니다.
- Cloud Datalab 실행
- BigQuery 쿼리 호출
- Datalab에서 그래프 만들기
- 머신러닝을 위한 Data Export
<실습 절차>
1. Cloud Datalab 실행
1) Datalab을 시작하려면 먼저 VM 인스턴스를 만들어야 합니다. Cloud Shell에서 다음을 입력합니다.
$ datalab create babyweight –zone us-central1-c
2) Datalab은 생성하는데 약 5분간 시간이 소요 되며, Cloud Shell의 상단에 웹 미리보기 아이콘으로 접속합니다. 생성되는 시간에 Big Query를 살펴 봅니다.

그림2 Cloud Datalab 초기화면
2. BigQuery 살펴보기
GCP에서는 Big Query 분석 예시용 Public Dataset을 제공합니다. 본 실습에서는 출산율 관련 Public Dataset을 사용합니다. ( bigquery-public-data.samples.natality)
1) BigQuery를 수행하기 위하여, BigQuery 콘솔 창으로 이동합니다. 콘솔에서 Compose Query를 클릭합니다.
그림3 BigQuery 콘솔
2) 쿼리 텍스트 상자에서 다음을 입력하고 Run Query를 클릭합니다.
SELECT
plurality,
COUNT(1) AS num_babies,
AVG(weight_pounds) AS ave_weight
FROM
`bigquery-public-data.samples.natality`
WHERE
year > 2000 AND year < 2005
GROUP BY
plurality
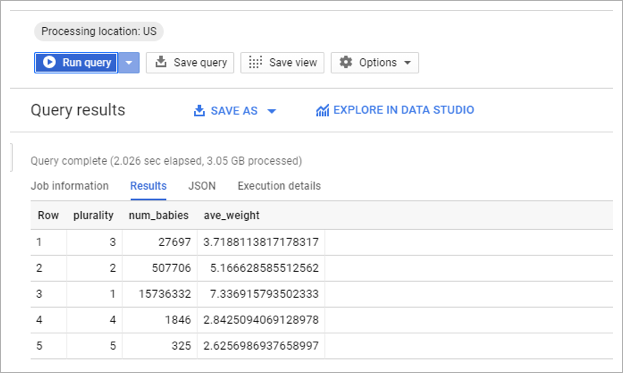
그림4 Query Result
쿼리 결과는 2000 ~ 2005년 사이의 다둥이 출생아 수치를 보여줍니다.
Ex) 세 쌍둥이는 총 27,697명이 태어 났으며, 평균 몸무게는 3.71 파운드 입니다.
3. Visualize data in Cloud Datalab
1) Datalab 화면에서 Notebook을 추가합니다.
2) 첫 번째 셀에서 BigQuery Python 라이브러리를 최신으로 업데이트 합니다. 셀에서 다음을 입력하고 상단에 RUN 버튼을 눌러 실행합니다.
!pip install –upgrade google-cloud-bigquery
결과 값이 많이 출력 됨으로 셀을 다음과 같이 접어서 숨길 수 있습니다.
3) 다음 코드를 삽입하여 BigQuery Python 클라이언트 라이브러리를 가져오고 클라이언트를 초기화 합니다. BigQuery 클라이언트는 BigQuery API에서 메시지를 주고받는데 사용됩니다. Shift+Enter를 사용하여 셀을 실행합니다. (RUN 버튼 클릭과 동일)
from google.cloud import bigquery
client = bigquery.Client()
4) 출생정보 관련 Public DataSet을 사용하여 1969년 ~ 2008년 까지 등록된 다둥이의 출산율을 조사합니다. 다음의 쿼리를 입력하고 Shit+Enter를 이용하여 실행합니다.
sql = “”” SELECT plurality, COUNT(1) AS count, year
FROM `bigquery-public-data.samples.natality`
WHERE NOT IS_NAN(plurality) AND plurality > 1
GROUP BY plurality, year ORDER BY count DESC
“””
df = client.query(sql).to_dataframe()
df.head()
쿼리 결과 데이터 프레임의 5행이 다음과 같이 출력됩니다.
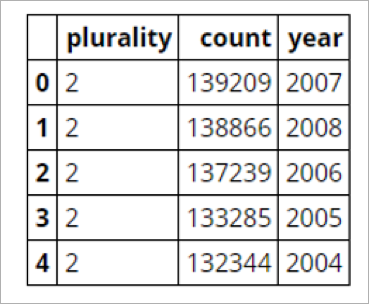
그림5 Query Result
5) 다음코드에서 4)번에서 실행한 데이터 프레임을 이용하여 데이터를 피봇하고 시간경과에 따른 복수 출생 횟수의 누적 막대형 차트를 만듭니다.
pivot_table = df.pivot(index=’year’, columns=’plurality’, values=’count’) pivot_table.plot(kind=’bar’, stacked=True, figsize=(15,7));
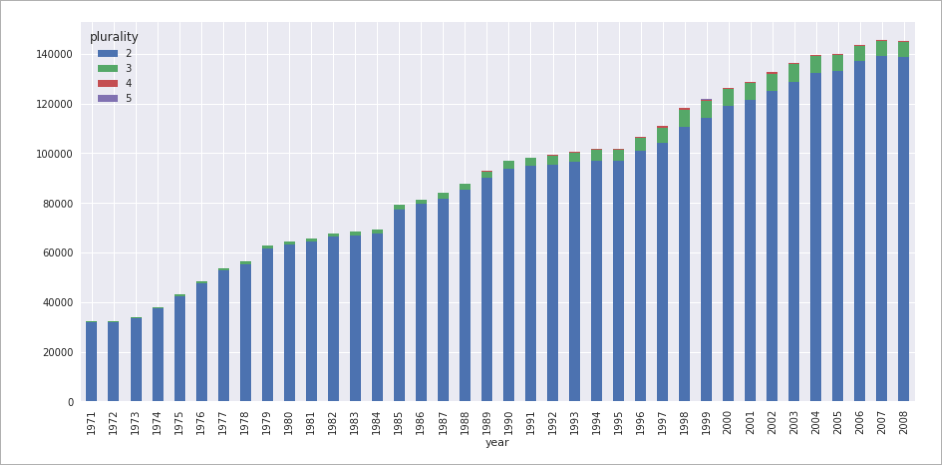
그림6 복수 출생 막대형차트
6) 다음으로 성별과 아기 체중의 상관성을 살펴 봅니다. 다음 셀에 아래의 쿼리 문을 입력하고, 막대 그래프를 생성합니다.
sql = “”” SELECT is_male, AVG(weight_pounds) AS ave_weight
FROM `bigquery-public-data.samples.natality`
GROUP BY is_male
“””
df = client.query(sql).to_dataframe()
df.plot(x=’is_male’, y=’ave_weight’, kind=’bar’);
미세하게 남자 아이가 더 무겁다는 사실을 알 수 있지만, 성별과 큰 차이는 없다는 사실을 알 수 있습니다.
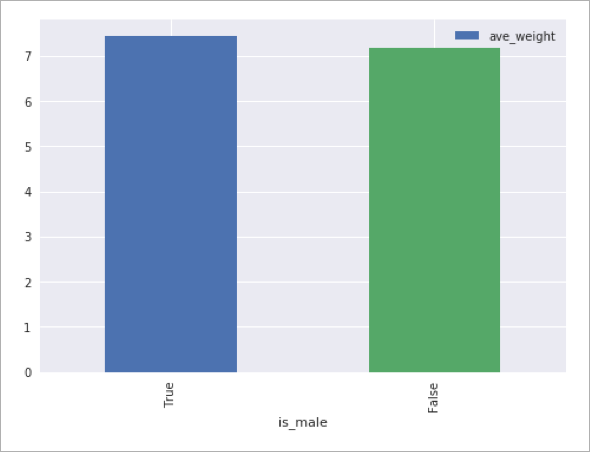
그림7 아기 성별에 따른 평균 무게
7) 마지막으로 임신 주차별 태아의 몸무게 평균 값을 구합니다. 다음의 쿼리를 입력하여 실행 합니다.
sql = “”” SELECT gestation_weeks, AVG(weight_pounds) AS ave_weight
FROM `bigquery-public-data.samples.natality`
WHERE NOT IS_NAN(gestation_weeks) AND gestation_weeks <> 99
GROUP BY gestation_weeks ORDER BY gestation_weeks
“””
df = client.query(sql).to_dataframe()
df.plot(x=’gestation_weeks’, y=’ave_weight’, kind=’bar’);
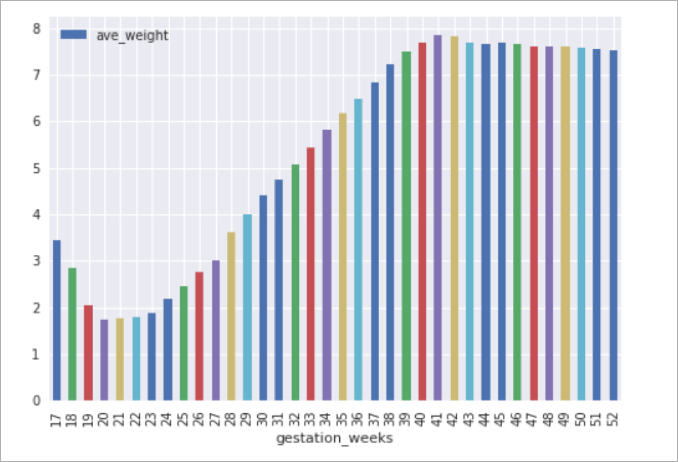
그림8 임신 주차별 태아 몸무게
구글 클라우드 플랫폼(GCP)에 대해 더 알고 싶으세요?
베스핀글로벌의 GCP 전문 엔지니어가 답해드립니다.